text preprocessing, text mining, conllu, filtering
Text Preprocessing: Tips & Tricks
Ajda Pretnar Žagar
Jun 26, 2024
A new video in our Text Mining series describes text preprocessing, a key step for any text mining task. Text preprocessing prepares the data for downstream analysis. Specifically, it constructs a list of items, typically words, that you wish to analyze further.
The default pipeline starts by lower-casing the text and then splitting the text into tokens. A token is a core unit of analysis. Often, this is a word, but it can also be a character, a sentence, or a phrase (n-grams). After tokenization, a basic filtering step removes English stopwords.
1. Choose the language
Some preprocessing steps are language-dependent. For example, filtering on stopwords depends on the language of the text. To change the language, select it from the dropdown or load your custom list of stopwords. Another language-dependent method is normalization, by which we typically mean lemmatization.
2. Customize
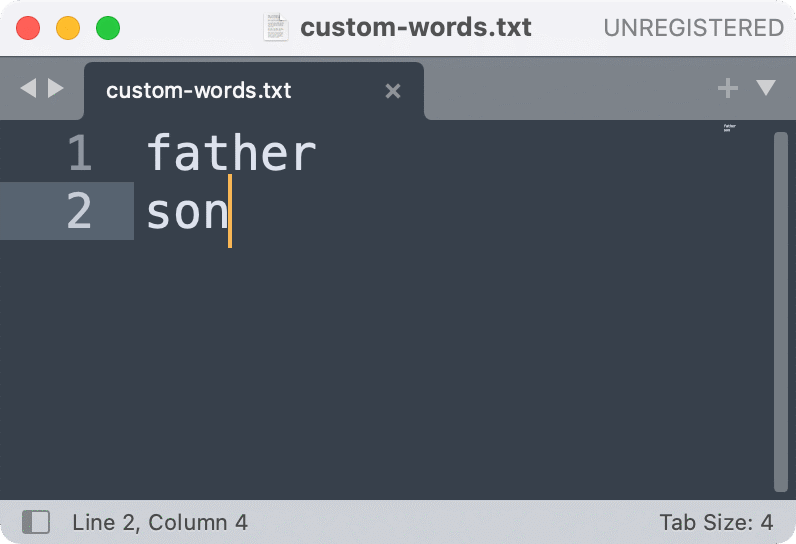
Loading a custom list of stopwords is easy. Create a plain text file and write each word on its own line. Save it as a .txt file. In Preprocess Text, first remove the English stopwords by selecting None in the dropdown. Then, click on the folder icon and load your custom list.
3. Beware of order
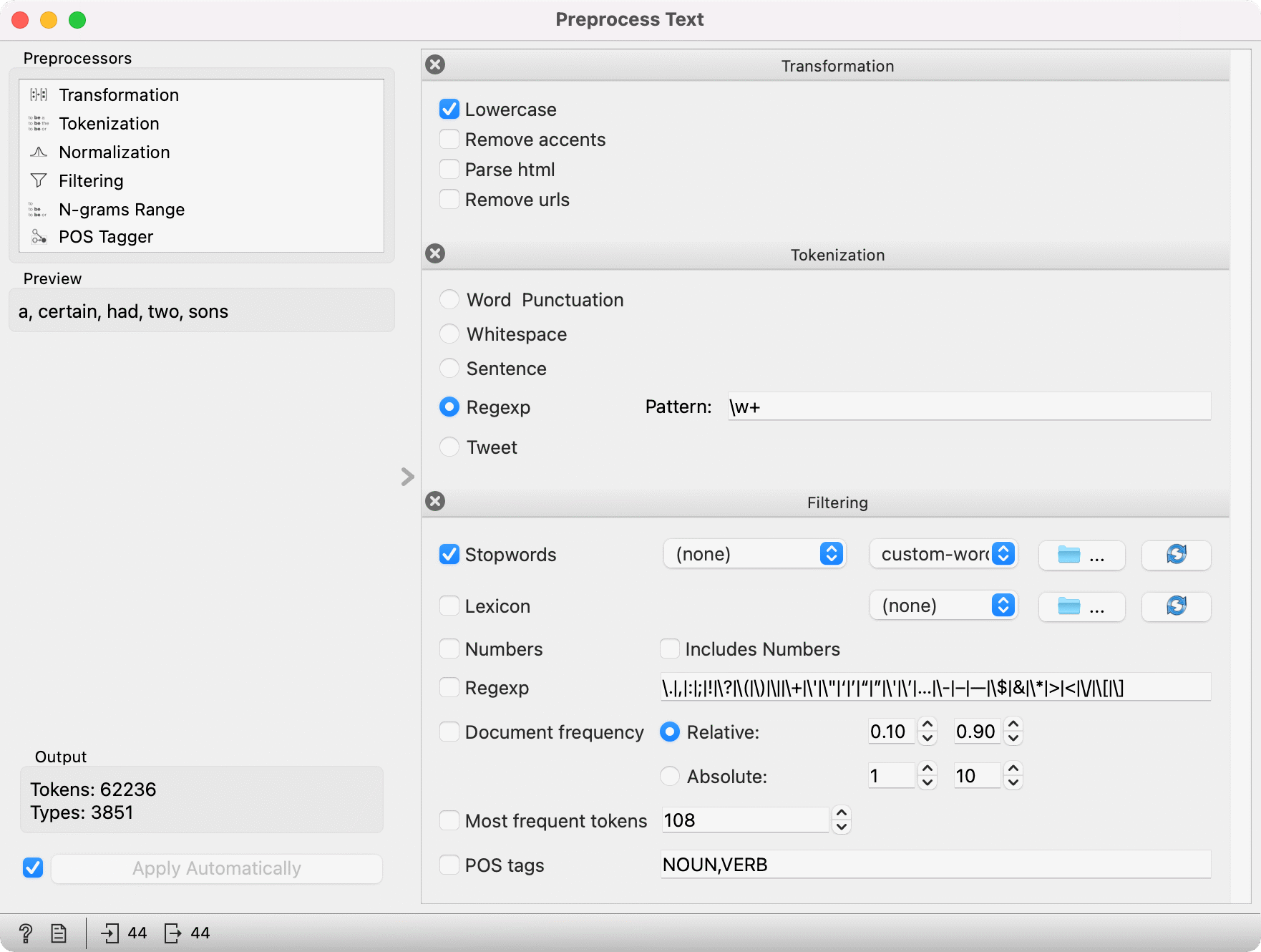
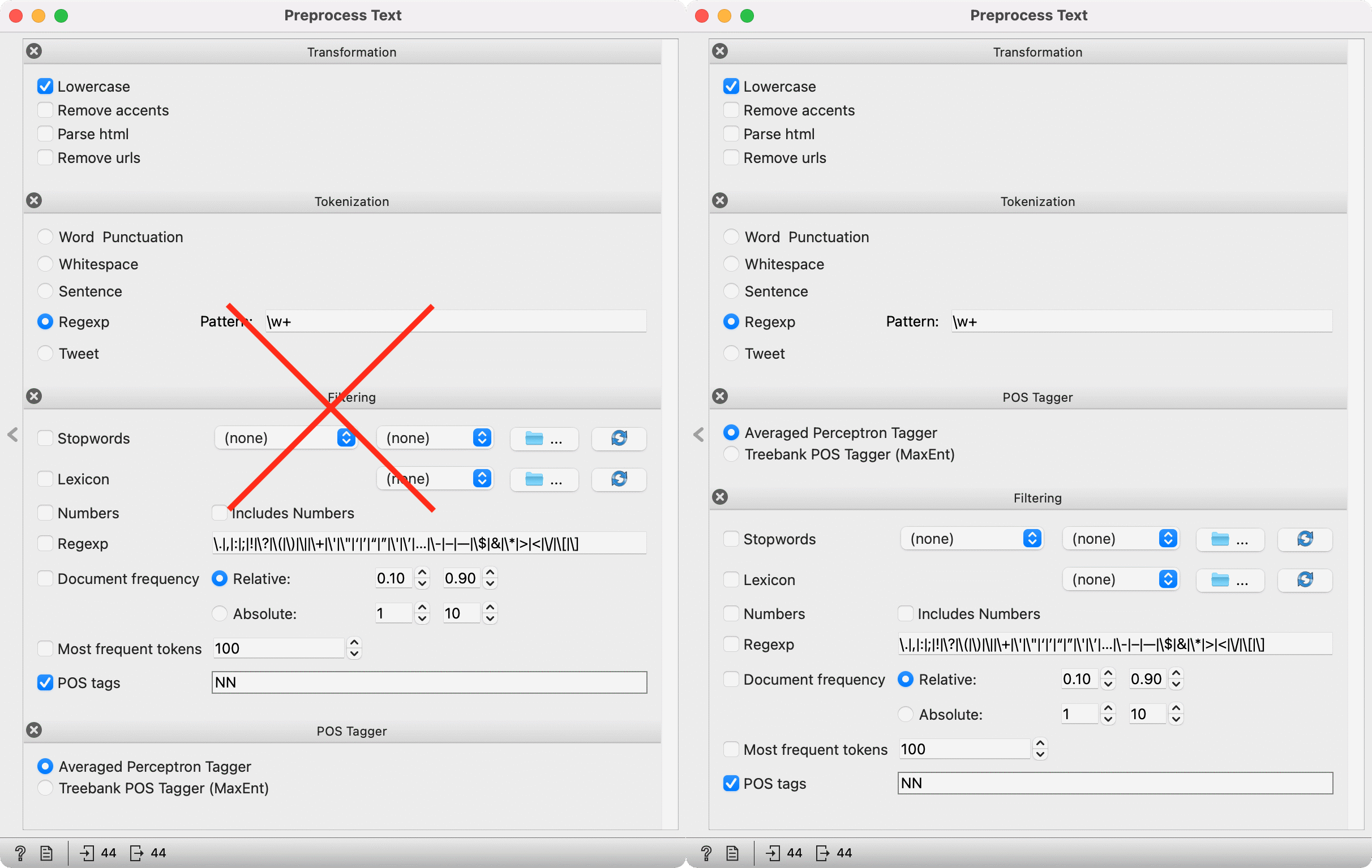
The order of preprocessing steps is crucial because each step is executed sequentially. For example, you cannot first filter on POS tags and then apply the POS tagging. The first filter won't work because there are no POS tags yet to filter on. Move the POS Tagger above the Filtering, and voila, tokens will be filtered correctly (only nouns retained).
4. Cut the noise
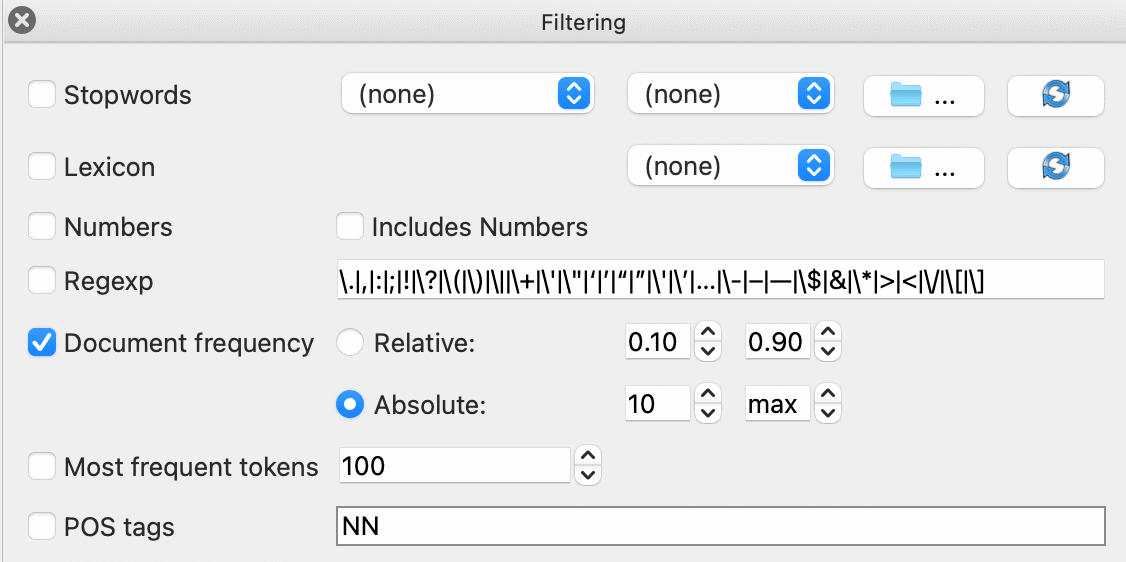
A typical step after preprocessing is creating a bag of words (bow). Since every word is a column in the bow representation, the table can get very big if we retain all the tokens. Often, it makes sense to discard the rarest words that occur in only a few documents. We can do this with the Document frequency option. We can filter on absolute (number of documents the token appears in) or relative frequencies (percentage of documents the word appears in). Say we wish to remove words that appear in less than 10 documents. Simply write 10 in the first box of the absolute filter. The filter will automatically update the second box to go to max. This way, you don't have to write the exact number of documents for the upper boundary!
5. Pick the steps
CoNLL-U files are terrific for digital humanities research because they contain linguistic annotations and are essentially preprocessed. Orange can read CoNLL-U files with its Import Documents widget. The widget will import lemmas by default, with additional options for POS tags and named entities. When working with CoNLL-U files, most preprocessing steps are optional. Remove them by clicking on the X button at each preprocessing method. For example, one can only retain filtering to remove stopwords or only keep nouns in the list.